Iron Vector
High-Performance Flink Acceleration
Iron Vector is a native, columnar, vectorized, high-performance accelerator for Apache Flink SQL and Table API. Built with Rust, Arrow and DataFusion, it provides significant performance improvements without requiring any code changes to your existing Flink applications.
Read the announcement blog post here.
Overview
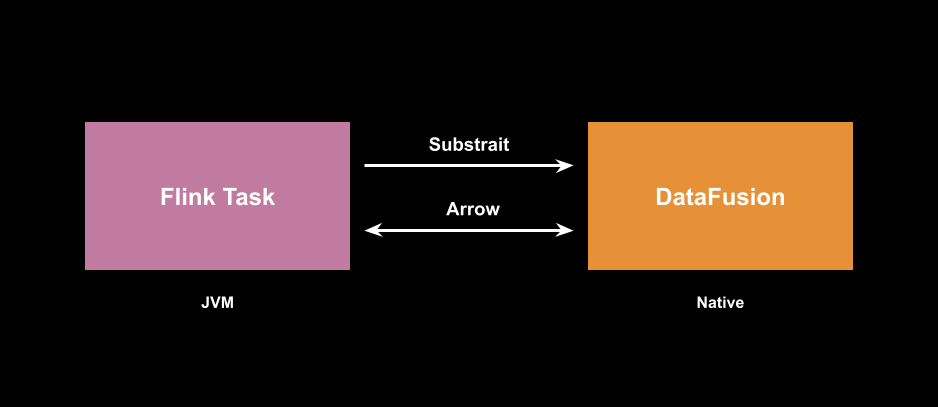
Built for Performance
Columnar Processing, Vectorized Execution
Iron Vector leverages Apache Arrow's columnar memory format to process data in batches, enabling SIMD operations and cache-efficient processing patterns that dramatically improve performance.
DataFusion Integration
Built on Apache DataFusion's query engine, Iron Vector provides native runtime execution and advanced query optimization.
Safety and Memory Efficiency
Rust's zero-cost abstractions and memory safety guarantees ensure optimal resource utilization without the overhead of garbage collection.
Native Formats
Iron Vector provides native support for popular data formats like Avro. It's able to deserialize data directly into Arrow format, eliminating unnecessary overhead.
Benchmarks
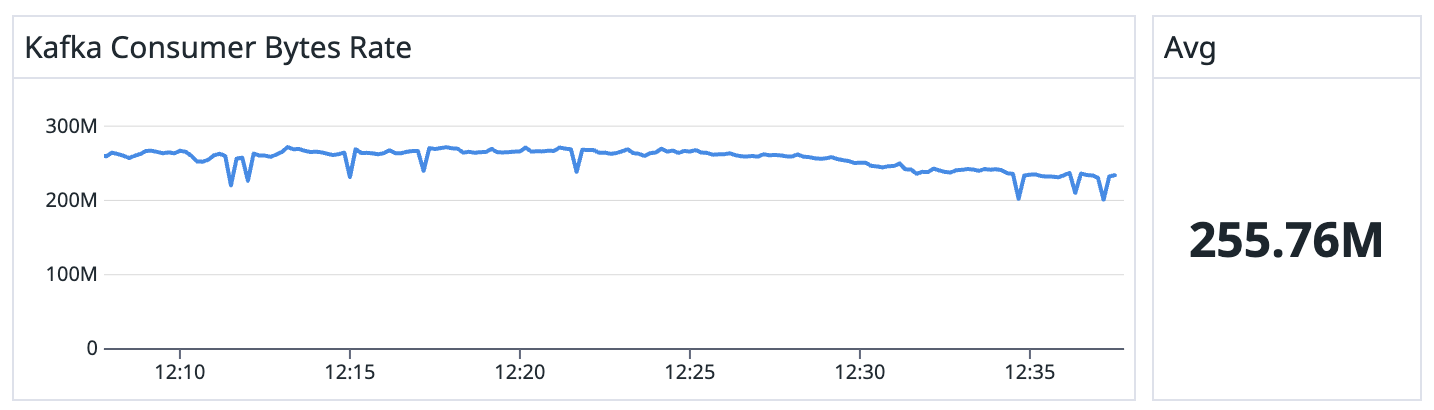
Vanilla Apache Flink
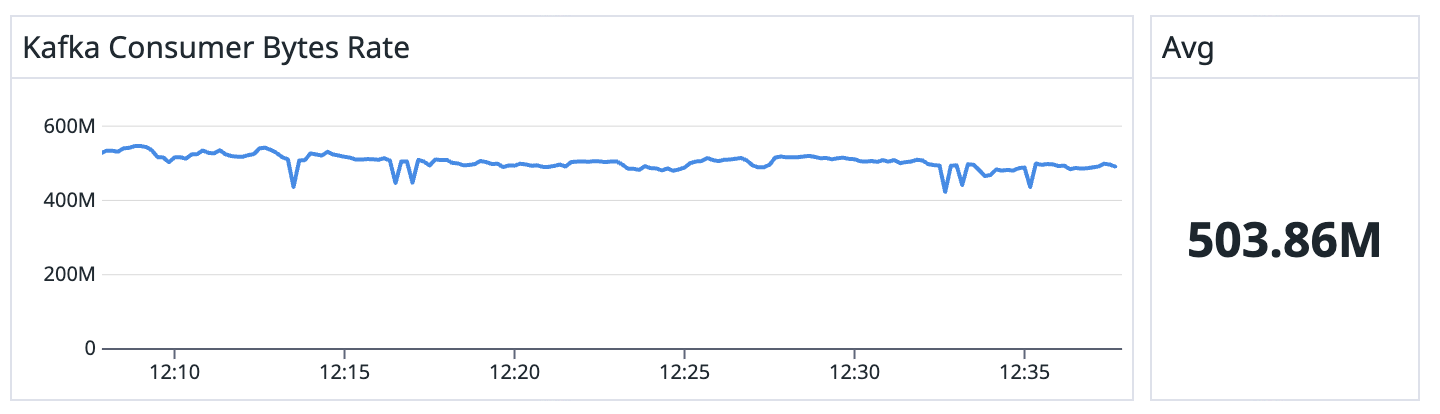
Apache Flink with Iron Vector
Extensive benchmarks demonstrate that Iron Vector can achieve up to 2x throughput improvements for stateless pipelines. This stays true for different topologies and parallelism levels.
Frequently Asked Questions
How does Iron Vector integrate with existing Flink applications?
Iron Vector is designed as a drop-in replacement for Flink's default execution engine. Simply add the Iron Vector JAR and the native library to your Flink cluster, no code changes are required. Your existing SQL queries and Table API operations will automatically benefit from native, columnar, vectorized execution.
Is it possible to use Iron Vector with a managed Flink offering?
Unfortunately, many managed Flink services do not currently support modifying system JARs. However, if your managed service allows it, you may be able to use Iron Vector.
What performance improvements can I expect?
Performance improvements vary by workload, but benchmarks consistently show up to 2x throughput improvements for stateless pipelines.
Can Iron Vector lower my Flink infrastructure costs?
Yes, the efficiency gains from Iron Vector can lead to significant cost savings. For example, you could be using Flink for streaming ETL or data integration scenarios, which means mostly using stateless pipelines. If you spend $5,000 a month on Flink compute, you could save up to $30,000 annually simply by enabling Iron Vector.
Is Iron Vector compatible with all Flink SQL or Table API features?
At the moment, Iron Vector supports any Flink connectors, and "stateless" operators: projections, filters, expressions and many system functions. Stateful operations like aggregations and joins are not yet supported, but we are actively working on adding support for these features.
Can I use Iron Vector with the DataStream API?
Not at the moment. However, if you use Flink Rows to serialize the data, you'll be able to leverage Iron Vector soon.
Ready to accelerate your Flink workloads?
Contact usor subscribe to receive updates