Introducing Iron Vector: Apache Flink Accelerator Capable of Reducing Compute Cost by up to 2x
Posted on by Yaroslav Tkachenko
Iron Vector is a native, columnar, vectorized, high-performance accelerator for Apache Flink SQL and Table API pipelines.
It’s easy to install, requires no code changes, and can increase compute efficiency by up to 2x (as of now).
The Problem
Apache Flink is well-known as a highly scalable data processing framework. Companies like Alibaba, LinkedIn, Uber and Netflix often share posts and talks, showcasing the scale Flink handles. It’s not uncommon to see hundreds of thousands of CPU cores being utilized.
But scalability doesn’t mean efficiency.
Efficiency is a complex topic; it’s not binary. There are many factors that impact efficiency at various scales.
For example, vectorization (via SIMD) is a very popular technique in the OLAP database space. It’s been around for more than a decade, but still, you typically have to use native languages like C++ or Rust to leverage it. Some basic support for SIMD was added in JDK 16, but even in the latest JDK, it seems to be marked as “preview”. And many Flink pipelines still run on Java 11.
Or a simpler example: JSON parsing. Flink JSON formats are based on Jackson, a popular Java JSON library. It’s mature and safe. But its performance can be absolutely atrocious compared to some newer libraries. It doesn’t take much code to make it 3x faster (I have proof).
And while this may feel like a highly theoretical topic, it can translate to significant cost savings. For companies spending $5,000/month on Flink compute for streaming ETL, enabling Iron Vector could translate to $30,000 in annual savings. Or you can keep your costs the same and handle twice the data volume. Either way, you’re getting more value from the infrastructure you already have. More on this below.
Why Build It?
I’ve been working with Flink for years. It remains the best stream-processing framework in many dimensions. It’s scalable, offers several APIs, and is very powerful when it comes to stateful stream processing.
But watching the broader data world evolve has been fascinating, and increasingly, it felt like streaming was being left behind. The Composable Data Management System Manifesto, the popularity of Rust and Apache Arrow, which even led to the Rewrite Bigdata in Rust movement. Apache DataFusion. Polars. The list goes on.
Native accelerators are not a new idea. Apache Spark has plenty of options, starting with Databricks’ Photon, Apache Gluten, Apache DataFusion Comet and many more. These projects proved that you could preserve a framework’s semantics and ecosystem while dramatically improving performance. It’s time for Flink to become faster.
Several months ago, I launched Irontools. I’m not trying to replace Flink - that would be throwing away years of battle-tested code and a thriving ecosystem. I’m making Flink better by giving it superpowers (like writing your UDFs in TypeScript, Go or Rust). Iron Vector is the next step: leveraging the RAD stack (Rust, Arrow, DataFusion) and bringing columnar, vectorized execution to stream processing without sacrificing any of Flink’s strengths.
Columnar Execution
Many people are familiar with Apache Arrow in the context of databases and query engines. Most of the streaming technologies operate in a row-based fashion. So, why is it a good idea to introduce a columnar format like Arrow? Aren’t we going backwards (to a micro-batch world)?
First of all, we need to distinguish between semantics and data layout. Flink operation semantics, just like the Spark ones, allow you, the user, to think about your computation in a record-at-a-time manner. And it can be perfectly fine to lay the data differently in memory.
There is nothing inherently bad in the idea of batching. The specific implementations (like micro-batching in Spark) could be criticized, but the concept itself is solid. Both Apache Kafka and Flink perform batching at different levels; you poll data from Kafka in batches, you send batches of Flink records between TaskManagers, you batch state writes, etc.
However, for actual processing, Flink insists on making both semantics AND data layout row-based. I disagree with it.
Micah Wylde, creator of Arroyo, explained it best in this blog post. To summarize, the efficiency gains you get by using columnar execution are significant: you get better CPU cache utilization and vectorization. And the latency is not really a problem when the throughput is high: you can fill the batches fast enough. If you’re processing 100,000 events per second, collecting 1,000 events takes just 10ms.
Finally, Flink already uses Arrow! You may not know this, but PyFlink has support for vectorized UDFs thanks to Arrow:
Vectorized Python user-defined functions are functions which are executed by transferring a batch of elements between JVM and Python VM in Arrow columnar format. The performance of vectorized Python user-defined functions are usually much higher than non-vectorized Python user-defined functions as the serialization/deserialization overhead and invocation overhead are much reduced. Besides, users could leverage the popular Python libraries such as Pandas, Numpy, etc for the vectorized Python user-defined functions implementation.
How Iron Vector Integrates with Flink
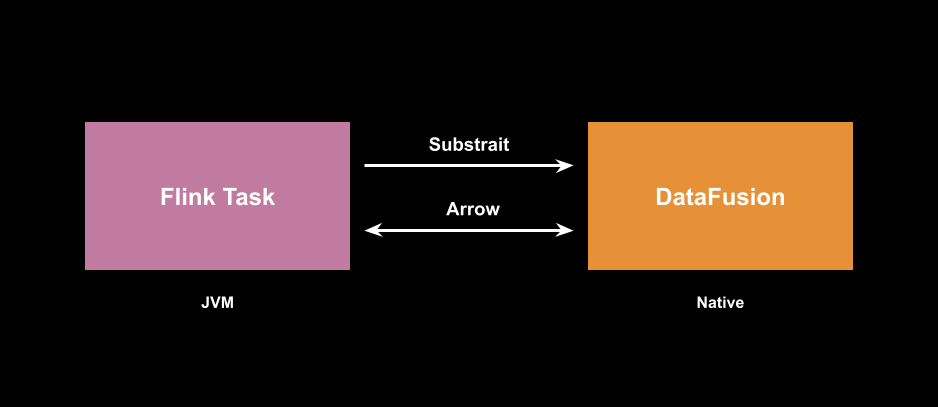
As a user, you continue to interact with the Flink SQL or Table APIs. Source and sink connectors stay the same (mostly, see below).
In most accelerators for other data processing technologies (like Apache Spark), it’s common to replace the runtime operators at the physical plan level. When it comes to Flink, the JobGraph abstraction can be thought of as a physical plan.
However, Iron Vector integrates with Flink at a lower level. It relies on Flink’s Task orchestration and replaces certain StreamTask subtopologies. This makes it possible to reuse as much of Flink’s Task management functionality as possible.
Iron Vector also relies on Flink’s Netty-based network exchange. But, instead of exchanging batches of RowData records, Arrow batches are used.
At the same time, Iron Vector still correctly propagates watermarks, emits metrics, etc.
For most supported operators, Arrow data is passed to the native execution runtime (implemented with Rust and DataFusion) over JNI without any data copying. The query plan and the table schemas are serialized using Substrait.
As an example, a Flink SQL statement like this:
SELECT name FROM test_table WHERE id > 100
Is converted to a physical DataFusion plan that looks like this:
VectorFilterExec: id@0 > 100, projection=[name@1, __row_kind@2]
RepartitionExec: partitioning=RoundRobinBatch(10), input_partitions=1
ChannelSourceExec
One interesting challenge was preserving Flink’s changelog semantics. Flink tracks whether each record is an insert, update, or delete using RowKind metadata. DataFusion doesn’t have this concept natively, so we carry it through as an additional column in our Arrow batches. It’s invisible to your SQL but ensures changelog streams work correctly.
DataFusion also leverages all available CPU cores by repartitioning data, also automatically.
Native Formats
Even if you have the best execution engine in the world, its performance will likely heavily depend on the underlying data source. Native accelerators are not an exception. Data needs to be deserialized from the source format (e.g. Parquet files in case of Spark or Kafka Avro topics in case of Flink) and converted to an optimized internal representation, like Arrow.
Row-based formats are still widely used in streaming environments, but Arrow (and similar formats) are columnar. We already covered why columnar formats are a good idea, but the serialization / deserialization cost alone could affect the overall performance (to the point where it erases any efficiency gains). For example, Binwei Yang, one of the Apache Gluten committers, noticed how Row-to-Column or Column-to-Row conversion can significantly impact Gluten performance.
That’s why Iron Vector ships with native format support, currently for Avro topics in the Kafka source. JSON topics and Parquet files for the file source to follow. The same will be applicable to sinks.
Here’s what “native format support” means:
- Input data, e.g. Avro records in a Kafka topic, is deserialized directly into Arrow batches. There is no intermediate representation (like RowData or GenericRecord).
- The switch to the native format happens automatically when Iron Vector detects a supported format.
- This can be disabled if needed.
In case of the unsupported formats, Iron Vector will let the source perform the RowData conversion first, and only then convert to the Arrow batches. However, this incurs a significant performance penalty. That’s why support for all popular formats is planned.
In the case of sinks, until native formats are introduced, Iron Vector leverages Flink’s ColumnarRowData, which is a row view into backing columnar vectors.
Current Limitations
Let’s be upfront about what Iron Vector can and can’t do today. Currently, we only support stateless operations, for example:
- Projections (SELECT fields)
- Filters (WHERE clauses)
- Expressions (math, string operations, CASE statements, etc.)
- System functions (CONCAT, REGEXP_REPLACE, etc.)
This covers a lot of ground for streaming ETL and data preparation workloads. If you’re enriching events, parsing logs, or cleaning data, Iron Vector can help today. But if you’re doing windowed aggregations or stream joins, you’ll need to wait.
The reason is simple: stateful operations are complex. We need to integrate with Flink’s state backends, handle exactly-once semantics, and ensure state migration works.
And I actually expect even better performance gains for stateful operations!
Also, Iron Vector currently focuses on SQL and Table APIs because those APIs 1) have a standard RowData format 2) don’t rely on UDFs as much (which are not supported at this moment; this will be addressed very soon). However, if you use Rows in your DataStream API pipelines, Iron Vector should be able to support your workloads eventually.
Benchmarks
Finally, benchmarks! I’d like to be brief in this post, but you can find all the results in this document.
We tested with a typical streaming ETL workload:
- Kafka source (Avro format)
- SQL transformation with filters and expressions
- Blackhole sink (to measure pure throughput)
. The SQL:
SELECT id, block_number, log_index * 2 as res, CONCAT('block_hash_', REGEXP_REPLACE(block_hash, '0x', '')) as res2
FROM KafkaTable
WHERE transaction_index > 40
When running a small pipeline (two TaskManagers, total parallelism of 4), it’s capable of achieving ~97% speedup!
The baseline run without Iron Vector:
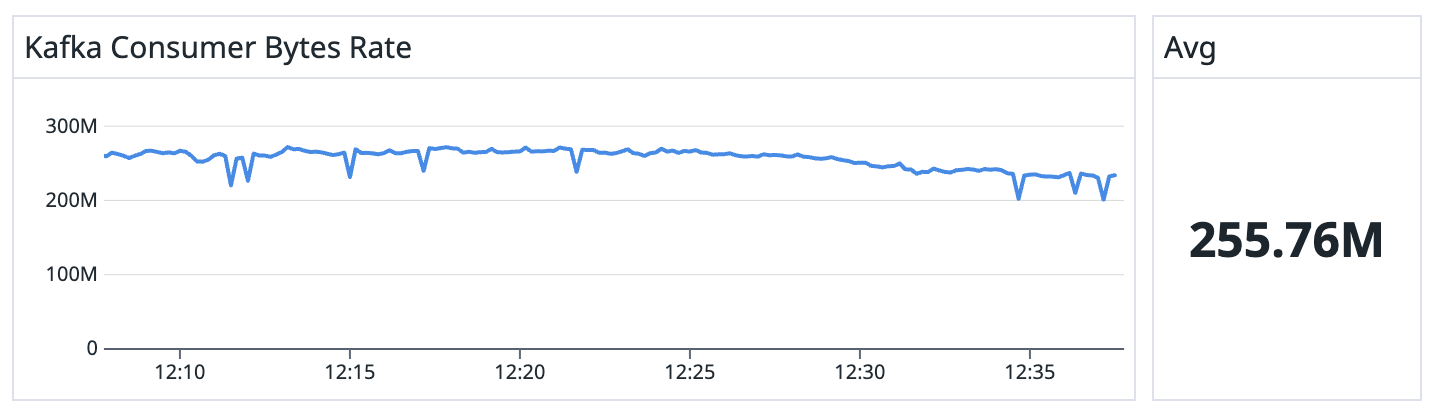
The run with Iron Vector:
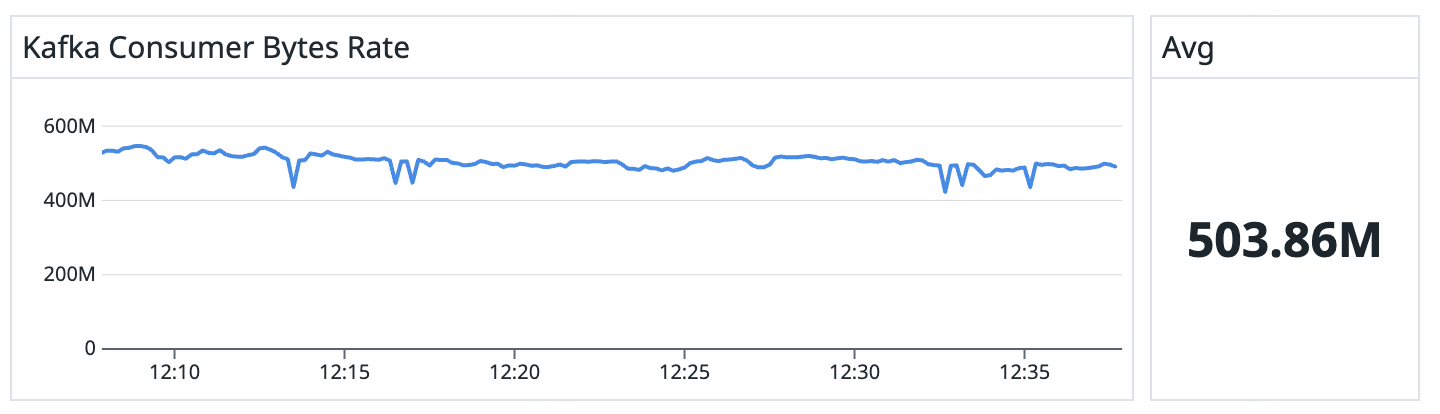
When object reuse is enabled, the speedup is reduced to “just” 46%.
These ratios persist in other scenarios, e.g. when using multiple sinks or when doubling the number of task slots (the speedup even increases slightly to ~100%).
Conclusion and Next Steps
The immediate benefit is obvious: lower costs or higher throughput.
For example, you could be using Flink for streaming ETL or data integration scenarios, which means mostly using stateless pipelines. If you spend $5,000 a month on Flink compute, you could save up to $30,000 annually simply by enabling Iron Vector!
The best part? It’s not an either/or decision. Iron Vector enhances Flink; it doesn’t replace it. You keep all of Flink’s benefits - the ecosystem, the operational maturity, the semantic model - while getting the performance of modern native execution.
But standardizing on Arrow opens up possibilities that go beyond performance.
Arrow is becoming the lingua franca of data systems. When your data is already in Arrow format:
- ClickHouse can read it directly via its Arrow interface
- DuckDB can query it without conversion
- You can share data with Python libraries (Pandas, Polars) efficiently
- New storage systems like Apache Fluss use it natively
We’re moving toward a world where data doesn’t need to be serialized and deserialized at every system boundary.
If you’re interested in exploring Iron Vector for your business, feel free to book a call. If you simply want to stay up to date with Irontools updates, subscribe to the Irontools newsletter using the form below.
Subscribe to receive updates